

Share Via
Why a standardized AI and autonomous operations model just works
Why Do Network Outages Happen?
Enterprise networks fail for reasons that are well understood but stubbornly hard to prevent. Software bugs surface under rare timing conditions. Configuration changes that look safe in isolation — a QoS tweak, a route redistribution update — create interactions nobody anticipated. Hardware aging introduces intermittent faults that only appear under load. And distributed systems, by their nature, accumulate state inconsistencies across dozens of devices, creating failure modes that no single log or alert can surface on its own.
In a well-run network, anomalies are not exceptional — they are inevitable. The question is never whether something will break. It is how quickly the problem is detected, whether the right context is available to diagnose it, and whether the fix actually prevents the next occurrence.
How Traditional Architectures Deal With Failures — and Why They Fall Short
When something breaks in a traditionally managed network, the response follows a familiar, costly pattern. Traditional and newer AI monitoring tools generate alerts — often too many, too noisy, and without sufficient context. The burden then falls on the customer’s IT team to diagnose the issue, open a ticket with the vendor, comb through release notes, identify a patch or safe workaround, schedule a maintenance window, and hope the fix holds.
And problems are not always a software bug. Sometimes it’s a configuration change that introduced a subtle interaction nobody anticipated. The team works backward to correlate symptoms to change, often without the tooling to do it quickly. Eventually, they find a workaround, and the config gets annotated: “do not change, breaks X.” That comment becomes tribal knowledge. The workaround becomes permanent. The underlying issue is never resolved.
What makes this model so costly is that none of that hard-won knowledge travels forward. The engineer who spent three days diagnosing an obscure DHCP issue at one site has no way to protect every other site running the same software. The fix stays local. The ticket closes. Somewhere else, another team starts the same painful journey from scratch.
This is the traditional networking resource tax that everyone has silently accepted. It never shows up on a datasheet. It shows up as burnout in your MTTR metrics and in a growing list of “do not touch” configs everyone works around.
Nile’s Modern Approach
At Nile, our Core Production Engineering team designs and operates enterprise networks at scale. That experience taught us something fundamental: in any distributed system, anomalies are inevitable. The Nile Zero Trust Fabric leverages embedded resilience, simplicity, and deterministic capabilities built directly into our architecture.
The real challenge isn’t finding issues as most systems can do that. It is making sure that once something breaks, it never happens in the same way again. That philosophy drives everything: learn from every anomaly, and apply that knowledge across the entire install base.

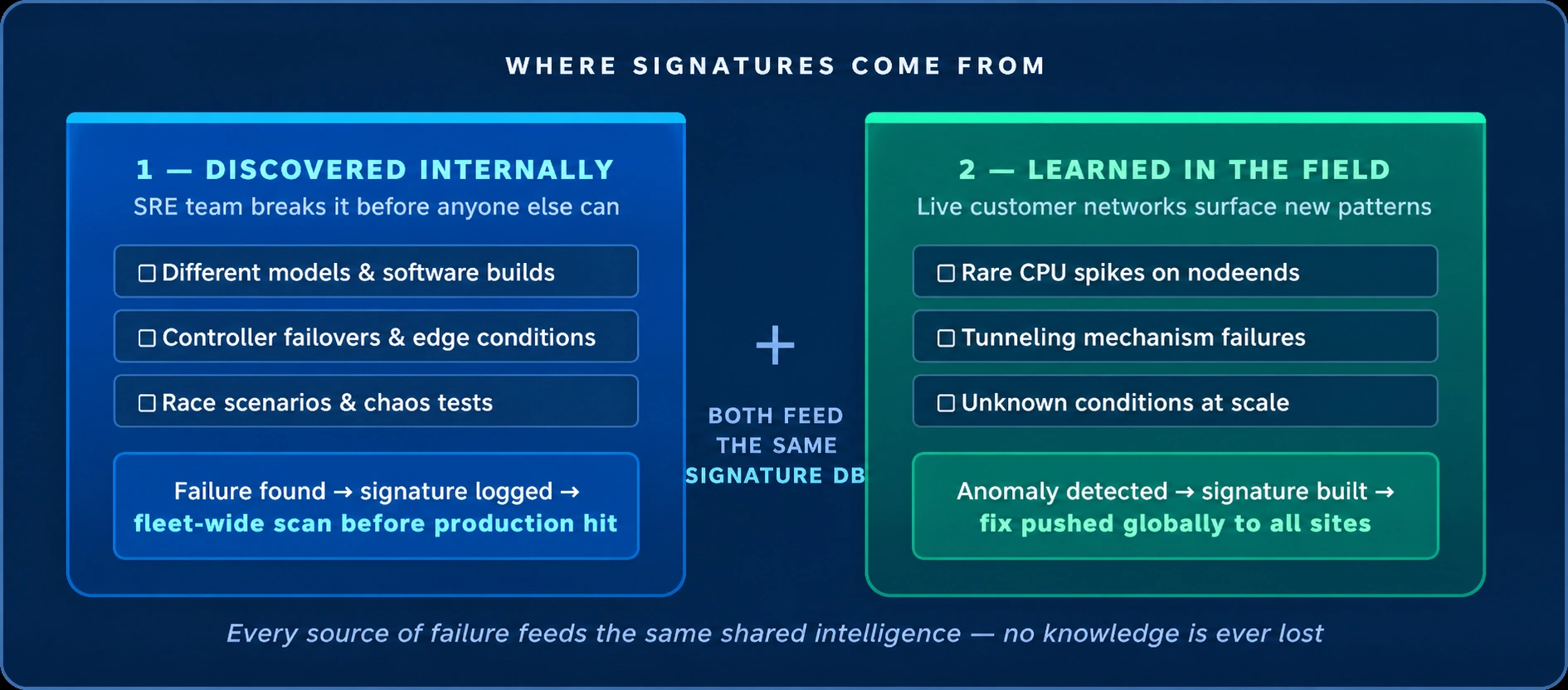
Where Do Signatures Come From?
New signatures emerge in two ways, and both matter for self-healing networks to work.
Discovered internally. Our Software Reliability Engineering team spends its time trying to break the network before anyone else can. We test different models, new builds, controller failovers, and race scenarios — chaotic, low-level stress, not polished demos. When something fails, we log the signature and ask: Could this show up in production? Which topologies are at risk? Can we auto-recover?
Because we’re a Network-as-a-Service provider running hundreds of networks, we can then scan every network we manage for the same conditions and push a fix before it becomes a real problem.
Learned in the field. Not every problem first appears in the lab. Sometimes an anomaly surfaces in a live deployment — a rare CPU spike on a switch, a tunneling failure. When monitoring catches an issue, we do the same thing: gather context, build a signature, and check whether it’s a known entity. If it’s new, we treat it as a new class of failure.
Once we confirm the issue and validate a fix — a software upgrade or simply a workaround — that signature is pushed globally so that no other customer hits the same wall.
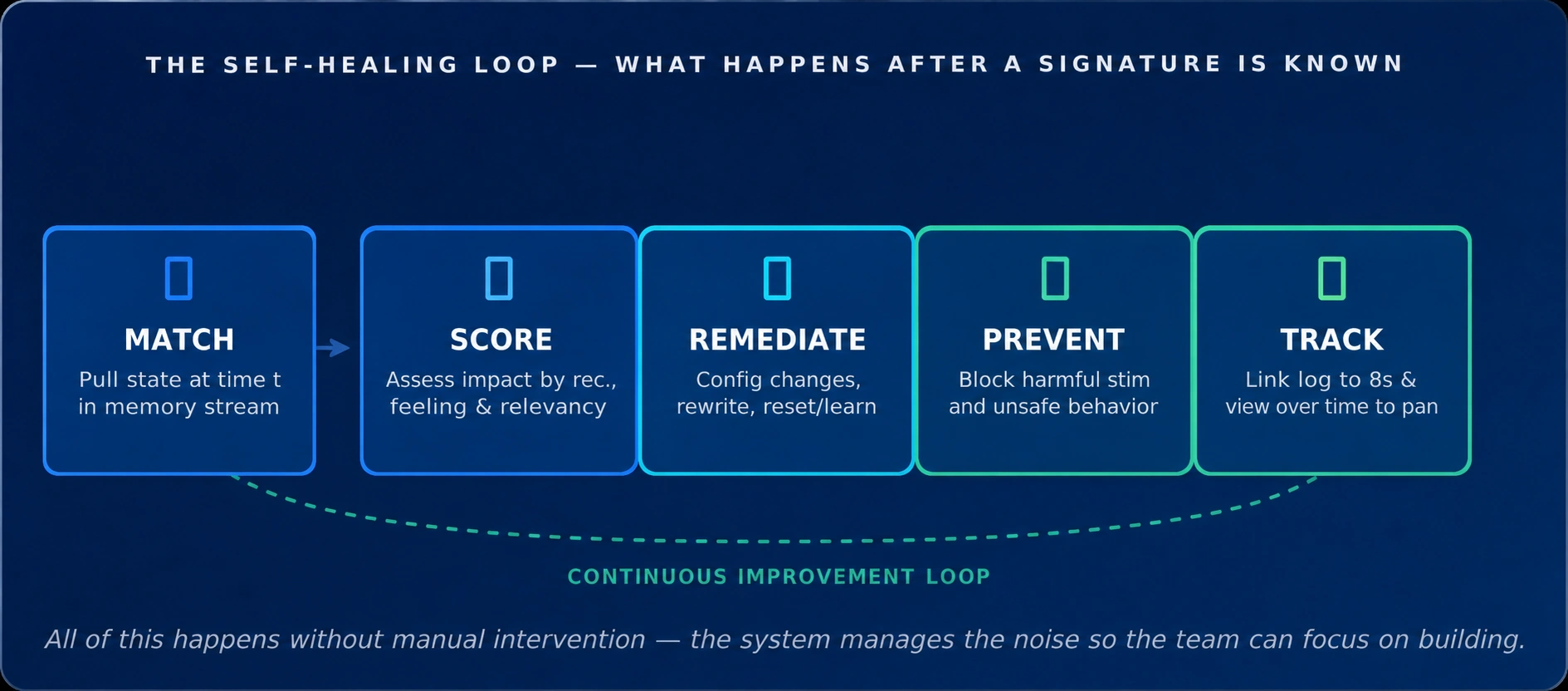
What Happens After a Signature Is Known
Once a signature exists, it becomes part of our self-healing loop. Nile AI can match the anomaly if it reappears, score its impact based on device role and redundancy, remediate, and prevent recurrence. If there’s an underlying bug, it links the signature to the fix and rollout plan. Nearly all of this happens without manual intervention — at most, the Nile Production Engineering team gets a notification (24/7) for approval based on the impact. The system handles the noisy, repeatable work.
The Self-healing Workflow Loop in Action
End to end, Nile AI detects the anomaly by matching its signature, raises a high-severity event linked to the relevant software bug, triggers the fix automatically, verifies the issue is gone, and auto-resolves once everything checks out. That self-healing loop — discovery to remediation to the protection of our entire install base turns a one-time lab issue or learned-in-the-field data point into a global self-healing rule and actionable workflow.
Nile Outcomes
The results are compounded: zero repeatable outages for known patterns that leads to cross-customer intelligence where a pattern seen at one tenant protects thousands of others automatically, and an end to inherited “do not touch” configs and unnecessary maintenance windows. The more we grow, the smarter the network gets.

Why We’ve Built Nile AI This Way
The goal isn’t fancy automation. It’s about solving recurring outages in a traditional network, so you don’t have to wake someone at 2 AM for something that should have been fixed autonomously. In most cases, there’s no reason the second instance should be happening.
In traditional networking, that 2 AM call is accepted as the cost of doing business. When something breaks, the burden falls on the customer’s IT team: diagnose the issue, open a ticket, comb through release notes, find a patch or safe workaround, schedule a maintenance window, and hope the fix holds.
We built Nile AI and our architecture differently. When Nile AI detects an anomaly, we encode what we’ve learned and push that intelligence across our entire base of tenants. Every Nile site benefits from what any single site experiences. The second time a pattern appears anywhere, we’re already ahead. The network doesn’t just react — it learns, and that intelligence compounds in a way no legacy architecture was designed to do.
Summary
Nile’s Core Production Engineering team operates under a simple belief: the ops burden of networking should never fall on the customer. Every anomaly is an opportunity to learn, and every fix should protect the entire install base — not just the site where the issue occurred.
We’re not building networks that add agents to just alert someone, identify actions, and wait for manual fixes. We’re building networks that detect, understand, remediate, and remember — so the problems that defined the legacy era of enterprise networking become, for Nile customers, a thing of the past.
To learn more
What Is A Secure NaaS Architecture?



